
In the realm of Big Data, architectures designed for massive data engineering tasks need to be fast, flexible, and scalable. While ELT (Extract, Load, Transform) solutions relying on the “Fivetran / Snowflake / DBT” type of combo has gained popularity in the recent years, these tools can quickly become cumbersome, costly, and limited as the scale of data processing increases.
In this post, we propose an alternative approach, primarily based on open-source tools. The goal is not to provide a one-size-fits-all solution, but rather to present a flexible architecture that can adapt to different use cases.
This approach centers around the concept of a lakehouse architecture, where we can leverage tools like Apache Iceberg, Kafka, and Spark to handle large-scale data ingestion, storage, and transformation. Although alternatives exist, this stack balances scalability, cost-effectiveness, and performance for bigger needs than for a small startup or academical projects. Let’s dive deeper.
1. Limitations of classical ELT / ETL architectures
Let’s consider a scenario in which a company has intensive data needs, and stores its transactional data (OLTP) with a Postgres database. The objective of an ELT approach is usually to extract this data for OLAP (Online Analytical Processing) usage, or for advanced product usage (such as reverse ETL).
A classic data stack (for example Fivetran, Snowflake, and DBT) may work well for small projects and companies. However, as your data and computational needs grow, you may face the following challenges:
-
Managing Fivetran ingestion connectors: while Fivetran excels at integrating various data sources, managing dozens or even hundreds of connectors can become complex, making synchronization across many datasets difficult to maintain.
-
Cost & performance of Snowflake: ingesting all input raw data into Snowflake for transformation can be expensive. Managing all the data transformation from within Snowflake may also be quite slow depending on your strategy and modeling, and can become difficult to maintain.
-
Transformation complexity with DBT: SQL transformations performed with DBT may become a bottleneck as your data and analytics grow. Complex transformations, multiplication of tables, and long dependency chains all can quickly turn DBT into a nightmare for larger teams. While DBT is ideal for small projects or companies, for more significant needs (or specific constraints) alternative tools like Spark are a better fit.
2. Objectives of a scalable data architecture
Our scalable ELT architecture should meet the following criteria:
-
Fast: data ingestion and transformations should handle high-throughput of large datasets, efficiently.
-
Scalable: the architecture should be able to scale seamlessly as the data volume and velocity increase.
-
Cost-effective: the architecture should be of minimal cost while maintaining performance, avoiding the high price tags of proprietary solutions.
-
Open-source: prioritizing open-source tools when possible is a great idea for better control, transparency, and most importantly to avoid vendor lock-in.
3. Architecture overview
We propose the overall architecture below, which meets our defined criteria and stays quite simple:
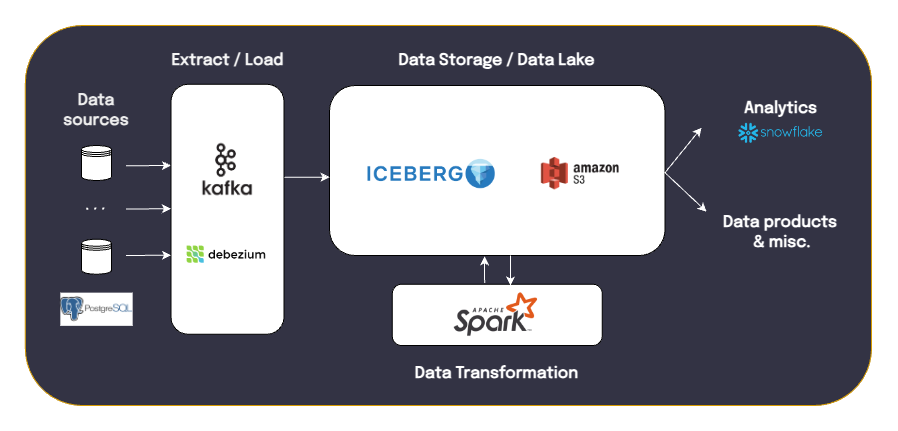 A flavor of the chosen data stack
A flavor of the chosen data stackThis ELT solution stores raw and intermediate results, allowing to keep track of changes and making debugging much easier. It also is very affordable, since data storage in S3 is quite cheap.
3.1 Data storage: S3 & lakehouse w/ Apache Iceberg
At the heart of this architecture lies a data lakehouse powered by Apache Iceberg on top of S3. Iceberg provides an open table format that allows for scalable, fast, and low-cost storage while ensuring consistency and atomicity in a distributed environment.
What is a Lakehouse and Open Table Format? Lakehouse architectures combine the benefits of both data lakes (low-cost storage, flexibility in file formats) and data warehouses (data consistency, performance). Open table formats like Iceberg, Delta Lake, and Hudi are the keys to making this possible.
Iceberg, in particular, wraps your data store and provides:
- Schema & partition evolution: enables changes in tables and partition schema without having to reprocess the existing data.
- Time travel: enables rollbacks to previous table states, which is very useful for debugging.
- Table branching & tagging: enables version control (similar to systems like Git), via the creation of branches or tags on your tables.
- Concurrency handling: efficient management of multiple readers and writers concurrently accessing the same data.
- ACID transactions: atomicity, consistency, isolation, and durability to ensure correctness in concurrent environments.
Over Parquet format, Iceberg is designed to manage large-scale datasets in distributed environments like Spark. It optimizes for performance, scalability, and ease of use. Iceberg was created to address the limitations of traditional table formats (like Hive or Parquet) when managing large datasets. For more details on Iceberg and Open Table Formats, check out this resource.
In our proposed architecture, Snowflake can sit on top of S3 to query processed Iceberg tables if necessary. You could also use Snowpipe to ingest only the transformed data for data analytics later, depending on your needs. In any case, this architecture allows to gain control over the data, and to keep the usage of Snowflake (or any other scaling OLAP solution) at minimal.
3.2 Data transformation: Apache Spark
For the transformation layer, we turn to Apache Spark, which provides greater control over computation and more flexibility in terms of code organization than DBT.
Spark is a great fit for processing large amounts of data on a lakehouse:
-
Wide range of built-in functions for transformations: beyond SQL, Spark supports more complex data processing tasks, such as tree traversal or denormalization that DBT might struggle with.
-
PySpark & Scala: PySpark-based Spark can handle lighter tasks and workloads, while Scala-based Spark is optimized for high-performance, heavy workloads.
-
Open-source: Spark’s open-source nature allows for customization and scalability at a low cost.
With this architecture, Spark is used as the primary transformation engine, performing ELT on data stored in S3. By storing raw data in S3 as a single source of truth, debugging and auditing becomes much simpler. At a later stage, for a more processed transformation, it is always possible to use tools like DBT (or SQL queries from Snowflake), once all the heavy work and processing has been done using Spark.
For more information on how to set up Spark with Iceberg, refer to this great guide from Dremio. Spark can also be deployed easily with AWS EMR.
3.3 Data ingestion: Debezium & Kafka
For a scalable, real-time ingestion, we leverage Debezium and Kafka. Debezium captures changes in data (inserts, updates, deletes) from a source database, and streams it into Kafka topics, which then writes this data to the storage (S3 + Iceberg).
-
Debezium: a change data capture (CDC) tool that tracks changes in your source databases (in this case, Postgres).
-
Kafka: streams the changes in the source databases (captured by Debezium) to an S3 bucket for storage and subsequent processing.
This strategy allows for efficient, incremental ingestion of data into the lakehouse, lowering costs and improving performance compared to bulk loading methods. Kafka can be deployed easily within a AWS EKS cluster.
4. Conclusions
Our proposed combination of Apache Iceberg, Spark, and Kafka for ELT creates a scalable and cost-effective architecture for managing large-scale data engineering tasks. By separating raw data storage from compute, using Spark for complex transformations, and leveraging Kafka for real-time ingestion, this architecture is highly flexible and future-proof.
On top of this architecture, Snowflake or even DuckDB can always be layered for small-scale on-the-fly analytics. If you’re building AI-driven products, the lakehouse paradigm provides a solid foundation for machine learning pipelines, reverse ETL, and operational analytics.