
In the realm of data engineering, a new term has emerged — the Modern Data Stack.
It may be perceived as another trendy buzzword (and maybe it is), but it encapsulates a transformative shift in how we approach data infrastructure and analytics tools. The modern data stack represents a departure from traditional methodologies to an era of self-service data utilization and streamlined transformation processes.
Defining the Modern Data Stack
At its core, the Modern Data Stack embodies the evolution of tools and practices within the data engineering landscape. It emphasizes two fundamental principles:
-
Self-Service Data Usage: empower data consumers, such as analysts and data scientists, by allowing independent access and manipulation of data without having to rely heavily on data engineers.
-
Ease of Transformation: facilitate the writing of transformations tailored to specific business needs, enabling analytics professionals to shape and visualize data according to their requirements, without extensive engineering intervention. For example, transforming the data in such a way that it can be plugged to any Business Intelligence (BI) tool, like Tableau or Metabase.
Does this make life easier for everybody? Yes, definitely.
Is it perfect? Not yet.
Why? In short, it does not cover all cases, and you unfortunately will still need to rely on adhoc scripting. Thus, the problem is not entirely solved, as we will see during the course of this article.
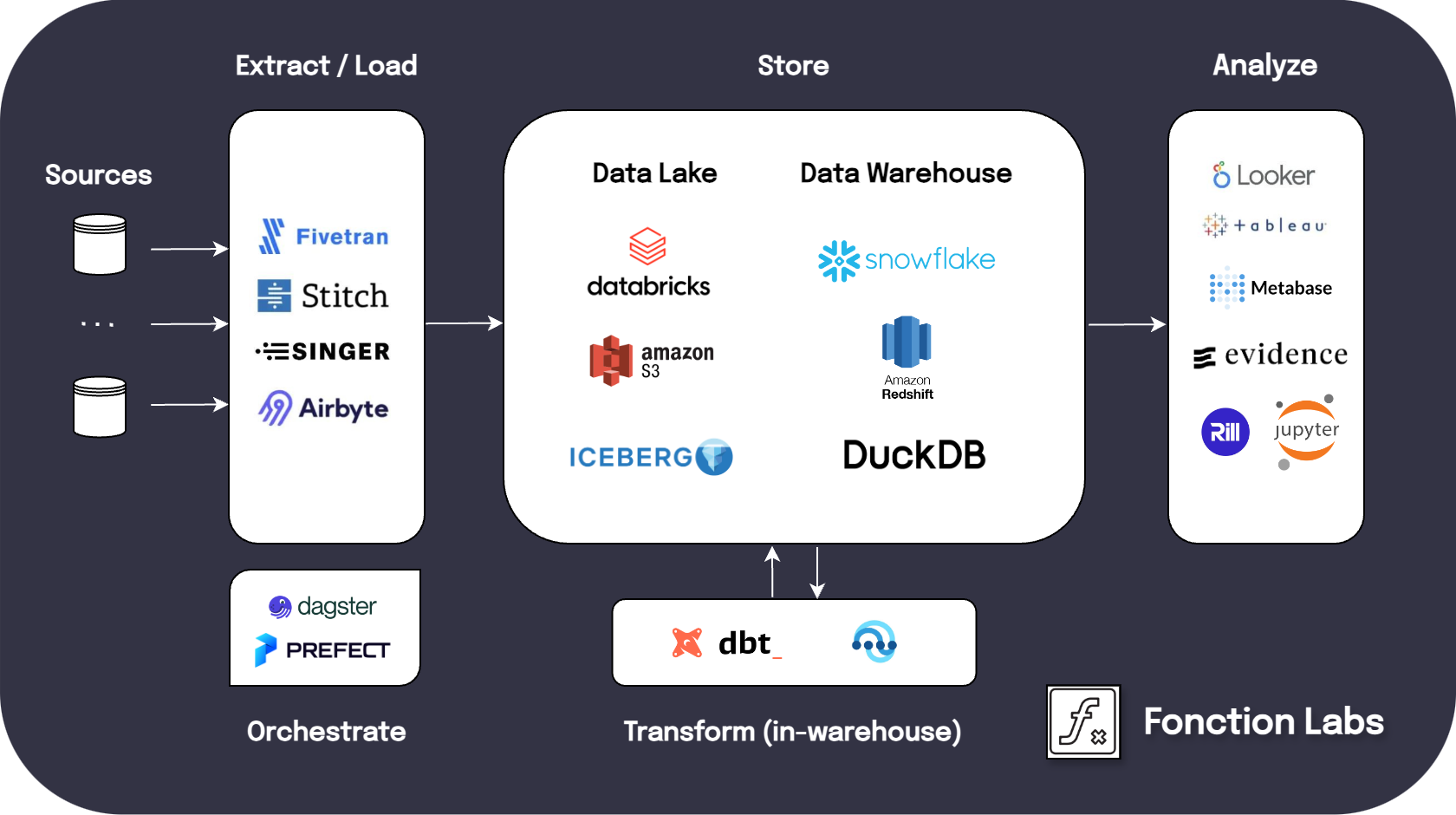 A flavor of the modern data stack
A flavor of the modern data stackTracing back: the evolution of data engineering
Let’s take a journey into the past. Where did it all begin?
Setting aside the foundational steps of BI and data engineering from the 70s to the 2010s, just a decade ago, Data Engineers still heavily relied on Airflow orchestrators. These orchestrators were tasked with executing ad-hoc Python or Spark scripts to manage extractions, transformations, and loadings. However, as the number of transformations surged and the sources multiplied, managing this complexity became daunting, demanding a profound and specific expertise in the system. Furthermore, because the infrastructure predominantly resided on-premise, local data warehouses and servers were bearing the burden of all orchestration tasks.
Consequently, even smaller-sized companies found themselves in need of sizable data engineering teams to keep operations running smoothly. This led to a pivotal shift in approach. People sought to abstract away complexities by embracing extract-load and declarative programming paradigms.
Solutions like Meltano, Airbyte, and Fivetran emerged, aiming to streamline processes. The transition from Extract-Transform-Load (ETL) to Extract-Load-Transform (ELT) gained traction, since it proved easier to perform transformations within the data warehouse itself rather than relying on a myriad of ad-hoc scripts.
The journey from reliance on Airflow orchestrators to the emergence of abstracted infrastructure solutions like Snowflake marks a significant chapter in the evolution of data engineering. As we reflect on this evolution, it appears evident that each milestone paves the way for further innovation and efficiency in managing data infrastructure and transformation.
The transformation journey: from ETL to ELT ✈️
A significant paradigm shift accompanying the modern data stack is the transition from Extract-Transform-Load (ETL) to Extract-Load-Transform (ELT). This transition entails a departure from reliance on Python scripts and tools like Airflow, towards a more SQL-centric approach. By leveraging pre-made connectors and prioritizing transformations from within the data warehouse, organizations can streamline processes and reduce dependence on custom, intricate scripting.
However, it is worth noting that while ELT simplified certain aspects of data transformation, it may not always represent the optimal approach. This is because it involves modifying the state of the data warehouse directly, rather than facilitating a continuous flow of data through pipelines. Hence, orchestration –typically via templating– still remains a critical component. We will delve deeper into this topic in a subsequent article.
A new role emerges: the Analytics Engineer 🤓
Central to the modern data stack is the emergence of the Analytics Engineer.
The Analytics Engineer bridges the gap between traditional data engineering and analytics, focusing on the transformation phases of the ELT pipelines. This means that the analytics professionals can concentrate on the data transformation processes, while the data engineers are now only concerned about optimizing the infrastructure and preparing deployments.
Declarative programming 📄
The modern data stack also emphasizes declarative programming, which enables users to define the desired outcome of the processes they have in mind, without having to specify the exact steps to achieve it.
This approach simplifies the transformation process and enhances the accessibility of data for non-technical users. While this is a significant improvement, complete declarative programming for ELT projects is not achieved yet. Most of the declarative programming happens at the Extract and Load parts (via tools like Meltano, Airbyte, or Fivetran), since it is often the part that is the most repetitive, and thus the most easy to abstract and declare.
There are no real solutions for declaring ELT transformations on data: you still need to rely on adhoc scripting and orchestration. This is a problem that is not entirely solved by the modern data stack.
Self-served cloud data warehousing 👤
The modern data stack leverages cloud data warehousing solutions like Snowflake, Google BigQuery, or Amazon Redshift to provide scalable, cost-effective storage for data. These platforms offer flexibility, scalability, and ease of use, enabling organizations to manage and analyze vast amounts of data efficiently.
In Snowflake, the separation of storage from computation is a key feature that enhances performance and scalability. The fact that it is self-served means data consumers can access and manipulate data without needing extensive engineering intervention nor infrastructure management.
The semantic layer and modern BI tools 📊
The semantic layer can be defined as an intermediate, understandable representation of the data for end-users, which sits between the raw data warehouse and the data analysis tools for the end users. This abstraction layer is growing in popularity, since it simplifies data access and interpretation.
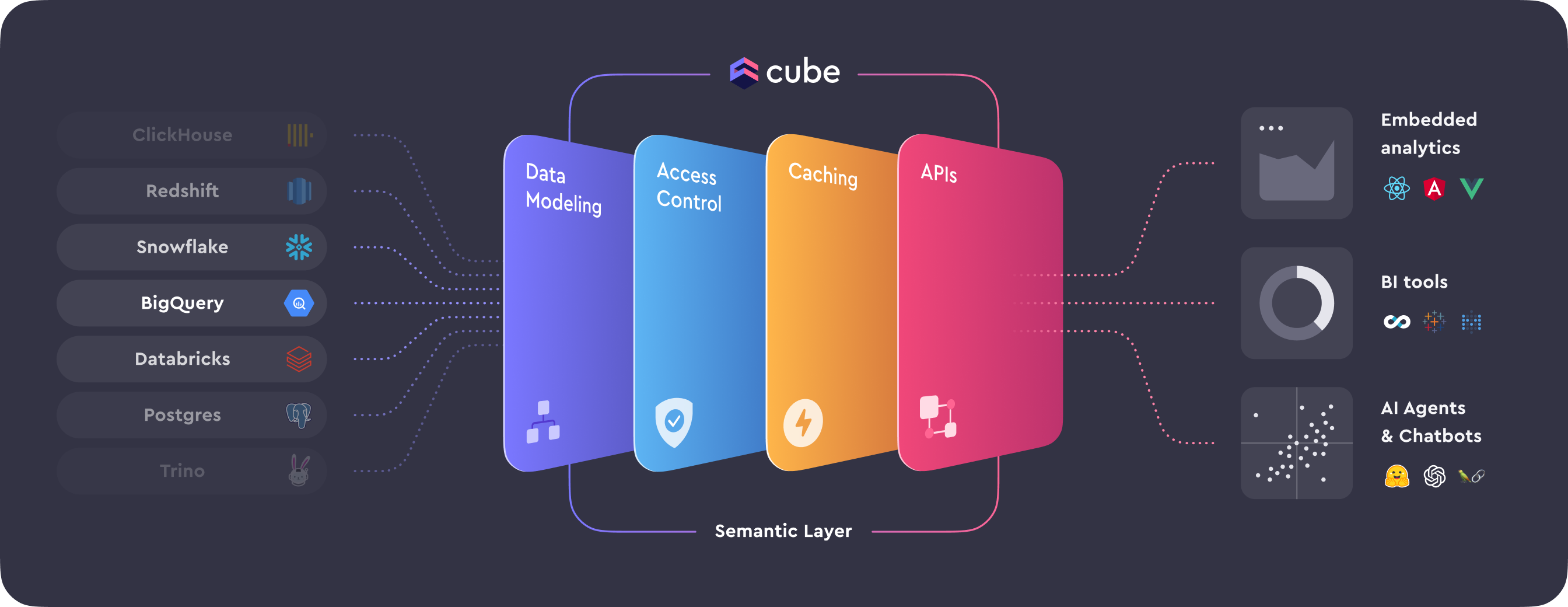
In the meantime, the modern data stack also incorporates modern BI tools like Google Looker, Sigma, and Rill. These tools provide a user-friendly interface for data exploration, visualization, and analysis, enabling data consumers to derive insights from data without deep programming expertise.
What could a modern data ecosystem look like?
Let’s take a closer look at the various components and services that can constitute a modern data ecosystem:
-
Storage:
- Cloud Data Warehouses & Data Lakes
Platforms like Snowflake, Databricks, Redshift, and BigQuery offer scalable storage solutions. - Data Lakehouses
Innovations like Apache Iceberg and Delta Lake (built on top of AWS S3, for example) provide abstraction layers for efficient data lake management. - Open Source options
PostgreSQL and DuckDB serve as viable alternatives, with DuckDB offering OLAP capabilities.
- Cloud Data Warehouses & Data Lakes
-
Extract-Load:
-
Transformation and Orchestration:
- Transformation Tools
dbt stands out, with its templating features tailored for ELT workflows. - Orchestration Frameworks
Dagster and Prefect (with Dagster gaining popularity) both provide robust orchestration capabilities for managing data pipelines efficiently. - Scripting Options
Python and Spark, alongside libraries like Polars, offer powerful options for more custom data transformation and processing.
- Transformation Tools
-
BI Tools:
- Visualization Platforms
Looker, Rill, and Sigma, along with traditional tools like Tableau and Power BI, empower users to derive actionable insights from data. - Open Source Alternatives
Platforms such as Evidence and Streamlit offer cost-effective and customizable options for building interactive data visualizations.
- Visualization Platforms
The beauty of the Modern Data Stack ecosystem lies in its versatility and accessibility. Even for small companies, building robust data solutions is now easier, faster, and more cost-effective than ever before. With the availability of free tools and open-source options, it is now entirely feasible to construct data pipelines alone, even on a single machine.
Stay tuned for more insights on leveraging these tools for low data usage scenarios in our upcoming article!