
Large Language Models (LLMs) have revolutionized how businesses operate, powering chatbots, agents, and specialized workflows in various industries. Despite their transformative potential, LLMs pose significant challenges in terms of stochasticity, reliability, and quality assurance.
Developing a robust Generative AI product requires more than flashy demos; it demands a systematic evaluation process that ensures performance, reliability, and trustworthiness.
While the practice of evaluating LLMs is still evolving, it is indispensable for creating dependable generative AI systems. This article outlines the key considerations, methodologies, and best practices for evaluating LLM-powered AI products.
Why is evaluating LLMs important
Evaluating Large Language Models (LLMs) is similar to software testing in traditional engineering—it serves as a critical mechanism for ensuring reliability and quality. Although evaluation methodologies for LLMs are not yet fully mature, they are indispensable for developing dependable Generative AI products. The challenge lies in addressing the inherent stochasticity and unpredictability of LLM outputs, which makes their performance harder to guarantee compared to traditional software.
Generative AI is transforming industries, enabling the creation of specialized applications such as chatbots, agents, and tailored workflows. However, while it is easy to craft impressive demos, building a robust AI product requires much more. Developers need to integrate advanced techniques for prompting, implement guardrails, design workflow architectures, and engineer the surrounding software infrastructure to create confidence in the product’s outputs. One key pillar of this process is the establishment of a robust evaluation system that tracks performance, ensures output quality, and provides feedback on changes to elements like prompts or configurations.
For example, prompt engineers often improve results by iteratively tweaking inputs to address issues such as hallucinations. However, such ad-hoc adjustments, done without systematic evaluation, risk introducing new issues elsewhere. This phenomenon, known as “eyeballing,” mirrors challenges in traditional software development and highlights the need for rigorous testing and evaluation frameworks. A systematic approach allows teams to quantify the impact of changes and maintain consistent quality across use cases.
Developing such evaluation processes is challenging, particularly because LLM-based products must be assessed on two fronts:
- General model performance, which assesses broad capabilities, often using general-purpose datasets. This type of evaluation is typically relevant for researchers training LLM (as well as developers) but can suffer from issues like dataset bias or task definitions that may not align with more specific usecases.
- Product-specific performance, which measures how effectively the model addresses specific problems within a particular context. This type of evaluation is more relevant for AI product developers and is the focus of this article.
Creating a robust evaluation system involves several key steps:
- Selecting the evaluation method (e.g., human vs. machine-based approaches).
- Building a representative benchmark dataset.
- Choosing appropriate metrics based on the problem’s requirements.
- Building the automated evaluation pipeline, and start evaluating.
- Optional - Integrating evaluation into a continuous AI development framework.
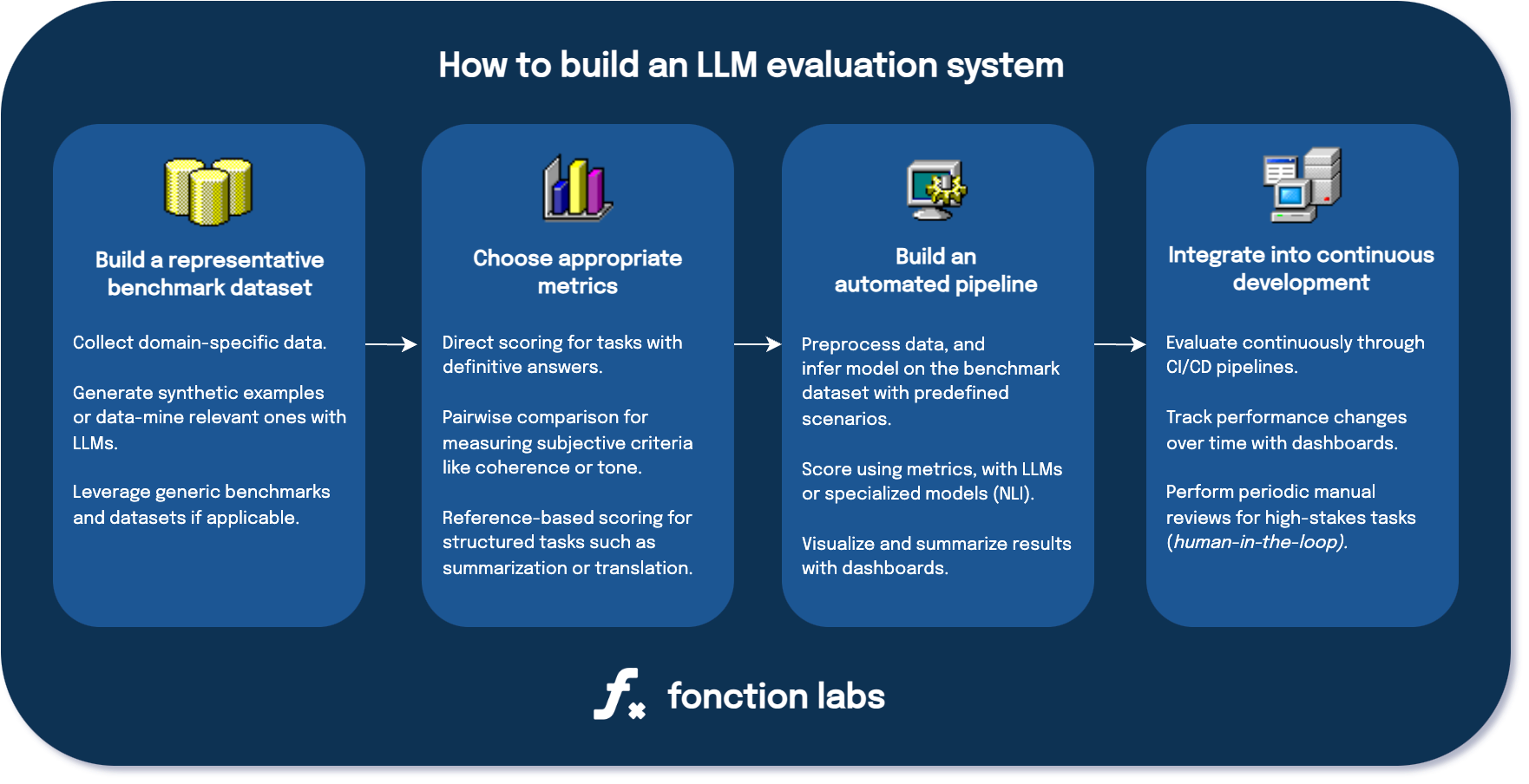 Steps to build an LLM evaluation system for safer GenAI applications.
Steps to build an LLM evaluation system for safer GenAI applications.By mastering these steps, developers can establish a framework for building and refining LLM-powered systems. This approach ensures that changes in design, prompts, or workflows lead to measurable improvements without unintended consequences. For specific tasks, readers will gain insights into selecting between different evaluation methods, such as direct scoring or pairwise comparisons, and determining the appropriate metrics—whether classification, correlation, or others. The ultimate goal is to create scalable, reliable AI solutions that inspire confidence and meet users’ needs.
How to evaluate LLMs
1. Selecting the evaluation method
Evaluation methodologies can be broadly categorized into human-based and machine-based approaches. The choice between these methods depends on the task’s complexity, interpretability requirements, and available resources.
-
Human-based evaluation involves human reviewers manually assessing model outputs against predefined benchmarks. While human evaluation is highly reliable for nuanced and subjective tasks, it is often costly, time-intensive, and difficult to scale. For example, manual evaluation might be indispensable for assessing creative writing outputs or deeply contextual tasks, but the associated effort limits its feasibility for iterative or large-scale evaluation.
-
Machine-based evaluation involves automated systems evaluating model outputs, either through smaller, specialized Natural Language Inference (NLI) models, or other LLMs. This method excels in scalability and speed, making it suitable for tasks with clear evaluation criteria, such as detecting policy violations or comparing outputs to pre-defined answers. Machine-based evaluations are particularly effective for tasks requiring interpretive consistency, as they eliminate human subjectivity and bias in repetitive assessments.
Constructing an effective benchmark is foundational to both approaches. While this task can be arduous and repetitive, especially if performed manually, automated techniques can assist in cases where clear and objective criteria exist.
For complex evaluations, LLM-based evaluators are emerging as an innovative and scalable solution for automating the evaluation process. Unlike conventional methods that rely on strict metrics like n-grams or semantic similarity, LLMs offer more nuanced and interpretive capabilities. They can handle ambiguous or subjective evaluation tasks with greater consistency and adaptability. Vanilla LLM models such as GPT4 can be used using specific prompting, but more specific models fine-tuned for some tasks, and special evaluation framework are leveraged to enhance performances.
Examples of LLM-based evaluators include:
-
SelfCheckGPT, which detects hallucinations by generating multiple responses and comparing them for consistency. It provides a cost-effective way to detect significant output errors, though it may struggle with subtler issues like partial hallucinations.
-
G-Eval, which employs a chain-of-thought (CoT) reasoning approach built on GPT-4 to provide detailed, structured evaluations. This method is particularly suited for tasks requiring deep contextual understanding and interpretive judgment.
In addition, fine-tuned evaluators, such as Shepherd and Cappy, offer domain-specific evaluation capabilities. While they show promise in improving reliability and performance, they often require extensive labeled data and computational resources to achieve generalizability.
Ultimately, the choice of evaluation method should align with the specific requirements of the task. Simpler models like NLI are well-suited for narrow, objective assessments, while LLM-based evaluators shine in interpretive and nuanced scenarios. Remember that the simpler, the better.
2. Building a representative benchmark dataset
While theoretically simple, creating a high-quality benchmark dataset may be in practice the most challenging aspect of the evaluation process. While datasets like HellaSwag (for completion tasks), MMLU (for multitasking), or domain-specific programming benchmarks exist, these general-purpose datasets rarely capture the nuances of more specific, “real-world” corporate use cases.
For most AI products, building a custom benchmark tailored to the target domain is essential. This often involves significant manual efforts, requiring domain expertise to design ideal-response examples that accurately reflect the task distribution.
While automation using LLMs can partially assist in this process by generating synthetic benchmarks, suggesting candidate responses, or mining relevant examples in the data, human verification remains critical for maintaining quality and relevance.
3. Choosing appropriate metrics
Defining evaluation metrics involves understanding what needs to be measured. The choice of metrics depends on the nature of the task and the evaluation goals:
-
Direct Scoring involves evaluating a single response against an objective criterion, such as detecting policy violations or factual correctness. This is suitable for clear-cut tasks with definitive answers, such as binary or multi-class classification, or objective question answering.
-
Pairwise Comparison judges which of two responses is the better one (or declares a tie), and is often used for subjective criteria like tone, coherence, or persuasiveness. Research shows pairwise comparisons yield more consistent results and better alignment with human preferences than direct scoring for qualitative assessments.
-
Reference-Based Evaluation compares generated outputs to a gold-standard reference, using fuzzy matching or advanced similarity measures. This approach works well for tasks like summarization or translation, where the target output has specific constraints.
Each metric type has strengths and limitations. For instance, pairwise comparisons provide greater reliability for subjective tasks, while direct scoring and reference-based methods excel in objective contexts. Combining these methods can provide a holistic evaluation framework. Additionally, emphasizing metrics like precision and recall (or sensitivity and specificity), rather than solely focusing on simple accuracy, ensures a more nuanced understanding of model performance.
4. Building the automated evaluation pipeline
An evaluation pipeline integrates the chosen benchmarks and metrics into a cohesive workflow. It typically involves:
- Data preprocessing to clean, standardize, and organize the data into datasets for evaluation.
- Model inference, which equates to running the LLM model on benchmark datasets with predefined prompts or scenarios.
- Automated scoring to grade answers inferred by the model, using the selected evaluation method and metrics. An integrated framework or UI can also be proposed to allow human-evaluators to efficiently evaluate the performance, or check specific situations.
- Visualization to generate reports or dashboards and summarize evaluation results.
Automating this process ensures efficiency and repeatability, especially when dealing with frequent model updates.
5. Integrating evaluation into a continuous AI development framework
In order to ensure model reliability and smooth performance maintaining over time, it is essential to embed evaluation into the AI development lifecycle. This step is only available for automated, machine-based evaluation methods. A continuous evaluation framework involves:
- Automated evaluations for rapid iteration. Machine-based evaluations using LLMs or NLI models allow quick assessment of changes during development, providing immediate feedback.
- Periodic manual reviews for high-stakes outputs. For critical use cases, periodic human review ensures alignment with nuanced expectations and identifies biases or gaps not easily detected by automated methods.
- Version tracking via CI/CD integration. Incorporating evaluations into CI/CD pipelines allow to track and monitor model performance with every update of the system. This involves linking results to specific commits or changes in the codebase, making it easier to identify the impact of modifications.
- Performance dashboards. Maintaining dashboards allows to visualize trends over time, highlighting performance improvements or regressions across key metrics and datasets.
By systematically evaluating pre-production and production environments, teams can monitor the effects of changes like prompt adjustments, fine-tuning, or new training data. This ensures stable performance and continuous progress towards optimal solutions. Automated pipelines, combined with periodic manual checks, create a robust feedback loop, helping teams deploy reliable and high-quality AI systems.
Examples of evaluation approaches with some use cases
Evaluating AI systems varies based on the use case, with metrics and methodologies tailored to specific tasks. For applications such as chatbots or content moderation, evaluation should emphasize conversational quality, ethical standards, and domain-specific relevance. Metrics like coherence, fluency, and informativeness gauge response quality, while frameworks such as Constitutional AI can assess harmfulness and bias in the responses. In order to meet business-specific needs such as customer support or technical assistance, more custom benchmarks and metrics will be needed.
Retrieval-Augmented Generation (RAG) applications add complexity by combining information retrieval with language generation. Key evaluation aspects include the relevance of retrieved references, the faithfulness of generated responses to source material, and overall question-answering accuracy. Metrics like context recall and semantic alignment are critical for retrieval evaluation, while datasets like HotPotQA or tools like RAGAS both support QA assessments. Human reviewers often set initial benchmarks, but scalable evaluations increasingly rely on advanced LLMs with chain-of-thought reasoning.
For GenAI applications designed for highly-specialized tasks, evaluations focus on task-specific KPIs. For instance, tasks like Named-Entity Recognition (NER) or Sensitive Information Detection require following metrics such as precision, recall, and F1-score. On the other hand, document summarization tools are assessed for coherence, completeness, and hallucination detection using frameworks like HaluEval. Another example of such highly-specialized applications are code generation systems, which prioritize execution correctness and solution efficiency, leveraging benchmarks like HumanEval. Finally, custom frameworks like Shepherd can enhance evaluation by fine-tuning on domain-specific datasets, although their effectiveness hinges on data quality and relevance.
The design of the evaluation process varies significantly across use cases, driven by the task’s complexity, data constraints, and performance expectations. Employing a mix of human and LLM-based evaluations often ensures comprehensive and scalable assessments tailored to each context.
Conclusion
Evaluating LLMs is both an art and a science, requiring a blend of technical rigor and contextual understanding. General benchmarks offer initial insights, but most applications require custom datasets and task-specific metrics for meaningful evaluation. Choosing the right methods —human-based, small model-driven, or LLM-based— depends on the task’s complexity, scalability needs, and resources.
The rise of LLM-based evaluators has transformed the evaluation landscape, offering scalable and consistent alternatives to manual approaches. Continuous evaluation frameworks integrated into development pipelines ensures models improve over time and adapt to changing needs.
By adopting systematic, context-aware evaluation strategies, it is possible to build reliable, high-performing GenAI applications that deliver consistent, real-world impact.
If you would like to know more about LLM evaluation for your GenAI project, get in touch now!